Large Language Models (LLMs), like GPT-4, are great generalists.
They’re versatile and adept at a wide range of tasks, from dishing out Dad jokes to thinking through high-level programming problems. As it turns out, they’re also exceptional as a tool for driving specialized experiences. When steered to fit particular needs, they can open new doors for practical applications in areas we’re just starting to uncover.
With this in mind, we recently built The Feedback Wizard – an LLM-guided experience, tuned to help anyone take a problem and transform it into constructive feedback that lands.
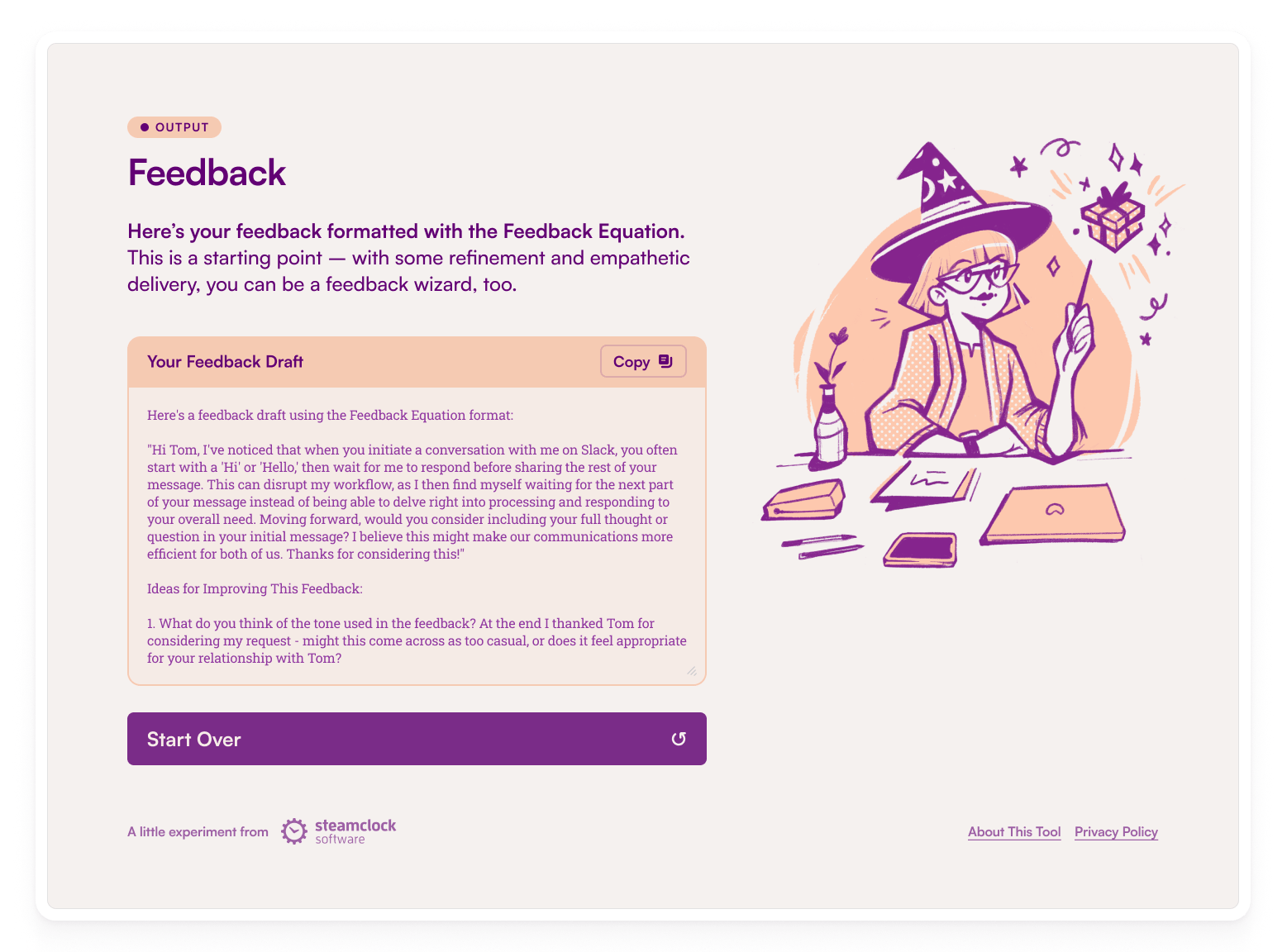
Why feedback? Because it’s the bedrock of thriving, high-performing teams. Feedback is an art and a science – the balancing of words and perceptions, to create a shared understanding as a foundation for solving problems. When done right, feedback is a catalyst for growth and performance. Our hope, with the help of LLMs, was to provide a tool versatile enough to adapt to the diverse needs of different teams and organizations, and specialized enough to truly help rein in the challenges of delivering constructive feedback well.
Building on LLMs today is a lot like assembling IKEA furniture without the manual – it can lead to some unexpected results (and a few “creative” interpretations) and, interestingly, feels a bit like giving feedback without a clear framework. Both require a mix of intuition, a willingness to adapt and improve, and a good sense of humour. Let’s explore the unexpected twists and turns of creating The Feedback Wizard, much like piecing together that mysteriously named Swedish bookshelf – just with more code.
The Ups and Downs of LLM Product Engineering
As is straightforward with prompt experimentation and OpenAI’s GPT APIs, we locked down a small proof of concept quickly. After this, we hit up against a number of surprising (and enlightening) challenges.
Consistent Output Formatting: Now Mathematically Impossible
At its core, The Feedback Wizard is a web app with a prompt pipeline that includes two consecutive requests to OpenAI’s GPT APIs: one that takes structured user input and creates clarifying follow-up questions, and one that generates a structured feedback draft (as well as some ideas for improving the draft).
As we discovered, consistently shaped outputs that can be reliably parsed are not a natural feature of LLMs, especially with temperatures above 0. OpenAI’s function calling is one approach for handling this, but without a robust parsing and/or structuring middleware of some kind, there are no strict output format guarantees (other than valid JSON) in this new age of probabilistic tooling.
OpenAI also recently added a seed parameter that provides some further control toward reproducible outputs. In our case, we wanted the output format to be consistent, but had no deterministic needs around the content itself – we wanted diverse and creative responses. On other projects since this one, we’ve had success with function calling paired with describing the shape of the JSON we’re expecting in the prompt, though this still fails occasionally in surprising and inconsistent ways.
Output Format (JSON):
{
"justification": "",
"score": xx
}
Confabulation and Choosing the Right Model
It’s well known that LLMs tend to confabulate. GPT-4 confabulates sometimes, but it has superior comprehension and reasoning abilities compared to GPT-3.5, giving improved results around several prompting techniques like few-shot prompting and chain-of-thought reasoning, among others. In our case, we needed to gracefully handle a breadth of quality user inputs, while maintaining an empathetic and collaborative tone. We also wanted to provide good coverage for a range of input qualities. Using GPT-3.5 gave okay results and was affordable during ramp-up, but as our prompting needs became more nuanced, we opted for GPT-4 and traded off considerably higher token costs and a higher chance of being rate-limited.
GPT-4 Turbo wasn’t available when we built The Feedback Wizard, but it can be a good alternative given its faster response times and cheaper cost. That said, it’s thought to be less capable than GPT-4 at providing detailed outputs, and in our experience, appears to rush through reasoning tasks, leading to results that don’t quite fit.
Token Economics and Napkin Math
Calculating the cost of each GPT-4 interaction was not unlike trying to estimate the total expense of an IKEA shopping spree – each individual item seems so affordable, but the total amount can be a shock, especially when you’re aiming for volume. We found that each pass through The Feedback Wizard on GPT-4 would lighten the proverbial Steamclock wallet by $0.06. With our token tally per request, this meant we could play host to about 53 users per minute before hitting our initial rate limit – not exactly a hoppin’ party. Luckily, our rate limits have since been increased substantially, but we opted to fall back to GPT-3.5 if we hit the rate limit, as a better alternative to full disruption of the tool.
Preventing Misuse
As they should, OpenAI has rules for using their models, which means product builders need to ensure the content we send stays clear of anything nefarious. If too many “bad” inputs are submitted to the API, OpenAI might decide to block or revoke access. As we’re all aware, the internet is a wild place, and sometimes people try to push the boundaries, so we decided to add OpenAI’s moderation APIs to be sure nothing slipped through. The moderation API isn’t reliably accurate, occasionally flagging reasonable inputs, but this was a tradeoff we were willing to make to ensure that our tool was protected.
Our Friend “Steve” and the Art of Testing Prompts
Tinkering with prompts is like trying to solve a mystery where the clues keep changing. The non-deterministic nature of these models (especially when run with higher temperatures) means you can expect the unexpected, with results shifting in unpredictable and sometimes baffling ways.
Here’s a fun fact: currently, we don’t have a “Steve” at Steamclock, but he’s our go-to guy any time we need to use hypotheticals to think through a situation – “Let’s say Steve is being a tyrant to clients…”, “Steve broke the build again…”. Imagine our surprise when “Steve” started making cameo appearances in our Feedback Wizard outputs. As it turns out, the LLM had developed a bit of a fascination with Steve, picking up on our example scenarios more than the actual queries, at least when no other name was provided in the real inputs.
Our solution: a playground, accessible in our development and staging environments. Playgrounds can be a great way to avoid deploying prompt changes and testing them in production (and the unexpected consequences of that). In our case, we integrated the user session, allowing us to adjust and try out updated prompts live in the staging app without impacting our “real” prompts – great for keeping “Steve” and other surprises in check.

Production – An “Eval-ution”
Sending The Feedback Wizard out into the world also had its share of surprises, a bit like the moment you step back to admire your IKEA assembled cabinet, only to realize you have a few leftover screws – it prompts immediate reevaluation and adjustment.
Even with careful testing in the playground, prompt changes carry the potential to trigger a cascade of intricate and unexpected outcomes, especially for edge case inputs, that were hard to test manually and measure. One tool to help with this is LLM evaluations, or evals. Like automated tests for LLMs, evals are a tool to assess how a prompt change will impact outputs across a range of inputs.
There are various open-source eval tools, but they’re currently pretty rough, particularly in setting specific triggers for these evals. Given the cost of GPT-4 calls, our goal was a system smart enough to initiate an eval based on particular conditions, performing an initial local sweep to identify issues and, if necessary, conducting deeper, more expensive evals on our outputs. This strategy aims for efficiency, avoiding the redundancy (and costs) of just running all evals blindly. Over time, and as we continue to experiment with LLMs across more projects, evals have become a pretty clear need that we haven’t yet had a chance to fully build out, but we have plans to expand on these more in future projects.
Embracing This Probabilistic Era
As we head into this new era of product building – defined by the unique strengths and challenges of LLMs like GPT-4 – we find ourselves at what feels like an important moment. This isn’t just an evolution in technology, it’s a revolution in how we, as designers, engineers and creators, approach problem-solving and innovation, and demands from us a fresh set of skills, tools, and mindsets.
The product landscape is shifting as well – we’re now seeing products beyond traditional and generalized chatbot applications like ChatGPT and into a world rich with specialized LLM-powered products.
The Feedback Wizard is a nice little example of this shift. It’s a pretty interesting (we think) demonstration of a non-chat LLM use case. If you’re curious to see how a little AI magic can level up the way you give feedback, give The Feedback Wizard a whirl! It’s fun, it’s insightful, and like that IKEA FLÄRDFULL lamp you bought on a whim, it might just be the sidekick you didn’t know you needed.
